Web Enumeration
Categories:
The primary goals of web recon are to:
- Identify assets (web pages, subdomains, IP address, tech stacks, etc.)
- Discover hidden information
- Analyze the attack surface
- Gather information that can be leveraged for further exploitation.
Similar to recon targeted toward other environments and services, web recon can be categorized into passive and active recon.
- Passive Recon avoids interacting with the target(s) directly.
- Active Recon interacts with the target(s) directly.
This article will mainly go over Active Recon techniques.
Subdomain Discovery
Subdomains exist as extensions to a main domain. For example, domain example.com may have subdomains blog.example.com, shop.example.com and so on. Subdomains can be set up to point to the same or different IP addresses as the main domain, making it an easy way to organize and access different network resources.
There are many ways to discover subdomains.
Subdomain Brute Forcing
Subdomain brute forcing uses a wordlist of common subdomain names (dev, blog, admin, mail, etc.), prepent each of them to the main domain and queries it against a DNS server, either a public one or a private one on the target network.
Tools such as DNSEnum can be used for subdomain bruteforcing
dnsenum --enum <DOMAIN> -f <WORDLIST>
Certificate Transparency Logs
Certificate Transparency (CT) Logs are public, append-only ledgers that record the issuance of TLS certificates. When a Certificate Authority (CA)issues a new certificate, it must submit it to multiple CT logs for anyone to inspect. CT logs exist to maintain the trust in the Public Key Infrastructure by exposing rogue certificates and the CAs that issues them.
However, CT logs also provides a publically available and definitive list of subdomains to attackers.
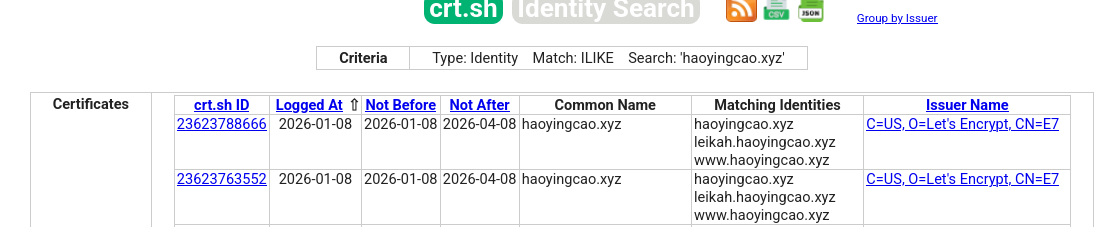
crt.sh is a simple, web-based search tool for CT Logs. Below is a search result for haoyingcao.xyz, which discovers subdomains leikah.haoyingcao.xyz and www.haoyingcao.xyz among others.
Virtual Host Discovery
Vitual hosts (vhosts) allow web servers to distinguish between multiple websites or applications sharing the same IP address. They are set up inside the web server’s configuration file. The web server then distinguishes requests for different vhosts via the HTTP Host header.
Gobuster can be used to brute force vhosts on a web server.
gobuster vhost -u http://<target_IP_address> -w <wordlist_file> --append-domain
Screenshotting Web Applications
When we have a large number of websites to test, rather than browsing them one-by-one manually, we can use create screenshots with automated tools such as EyeWitness and Aquatone. These tools will visit each website, create a screenshot, and compile a report in HTML for easy review.
EyeWitness
EyeWitness is designed It can be provided a list of URLs to visit using -f, as well as XML-formatted Nmap reports using -x.
eyewitness --web -f urls.txt -d haoyingcao.xyz
eyewitness --web -x nmap.xml -d haoyingcao.xyz
The report will group websites by their perceived value. EyeWitness attempts to identify if the website is a commercial or open-source application. It also provides other information such as the HTTP reponse headers as well as default credentials for any common applications if finds.
Other options for this tool include:
--user-agent: Specify value for User-Agent header for the requests.--proxy-ip: Specify IP address of a web proxy.--resolve: Resolve IP/Hostname for targets-d: Directory name for report--threads: Number of threads to use
Aquatone
Aquatone is a tool similar to EyeWitness written in Go. We can use Aquatone by piping it a list of targets, allowing for easy intergration. The target can be in the form of URLs, domains, and IP addresses.
cat targets.txt | aquatone
Alternatively, we can also feed it Nmap XML report if we run Aquatone with the -nmap option.
cat nmap.xml | aquatone -nmap
By default, Aquatone creates the report within its current working directory. The report structure looks like the following:
aquatone_report.html: Main HTML report that we can open with a web browser.aquatone_urls.txt: A file containing all responsive URLs.aquatone_session.json: A file containing statistics and page data. Useful for automation.headers/: A folder with files containing raw response headers from processed targetshtml/: A folder with files containing the raw response bodies from processed targets. If you are processing a large amount of hosts, and don’t need this for further analysis, you can disable this with the -save-body=false flag to save some disk space.screenshots/: A folder with PNG screenshots of the processed targets
Report destination can be specified using -out argument or the AQUATONE_OUT_PATH environment variable.
cat targets.txt | aquatone -out aquatone_report
export AQUATONE_OUT_PATH="~/aquatone"
File/Directory Discovery
Each website or applications contain different files, directories and endpoints. Other than navigating to them like normal users, we can also discover them in multiple ways:
robots.txt
robots.txt is a simple text file placed in the root of the website (e.g. www.example.com/robots.txt). It tells bots and web crawlers of which parts of the website they can or cannot crawl. From the attacker’s perspective, robots.txt can help us discover potentially interesting files and redirectories.
Example robots.txt:
User-agent: *
Disallow: /admin/
Disallow: /private/
Allow: /public/
User-agent: Googlebot
Crawl-delay: 10
Sitemap: https://www.example.com/sitemap.xml
File/Directory Brute Forcing
Directory Brute Forcing is often effective as many website has similar directory naming convention, especially if they use commonly available web technology. Gobuster and Ffuf can be used for this purpose:
Gobuster:
gobuster dir -u <URL> -w <WORDLIST>
- Useful optional arguments:
--follow-redirect: If a certain endpoint returns a redirect status code (301, 302), gobuster will follow the redirect automatically.-x: File extension(s) to add to the brute force, can handle comma-separated list.-t <THREAD_COUNT>: Adjust the amount of threads-k: Skip TLS validation, useful if the website uses a self-signed certificate.-b: Blacklist status codes, can handle comma-separated lists and ranges.--xl: Blacklist responses with a certain length, can handle comma-separated lists and ranges.
Ffuf is a web fuzzer that can also be used for directory busting. It will replace the keyword FUZZ with each entry in the wordlist.
ffuf -w <WORDLIST> -u <URL>/FUZZ
Git Repo Dumping
Suppose a .git directory was found on web server. This almost certainly means a Git repository is hosted on the web server. We can use a script such as git-dumper to dump the Git repository. This could allow us to read the web application’s source code, find vulnerabilities or discover sensitive information.
python git-dumper.py <URL> <repo_dump_path>
We could use a tool such as trufflehog to scan the repo for any leaked credentials such as passwords, tokens, or API keys.
trufflehog --repo_path <repo_dump_path>
Parameter Discovery
Web pages may use GET and/or POST parameters to send data to be processed by the back-end. These parameters may open up vectors of attacks if not validated and sanitized properly. While we can discover parameters while we visit and interact with the pages, there may be hidden parameters that we can possibly reveal through fuzzing.
The procedure for parameter fuzzing is to first fuzz for parameter name, then fuzz their values. We need to establish a baseline for how the server responds to normal requests (e.g. status code, content, headers, timing), which will be used to differentiate interesting input that make the web server behave differently, through which may be able to discover page parameters and interesting values.
GET Parameters
GET parameters and their values embedded within the URL with a ?, and each subsequent parameter is linked to the previous one using &.
http://example.com/index.php?var1=value1&var2=value2
We can fuzz for possible GET parameters using ffuf by placing the FUZZ keyword as the name of the parameter, and set a dummy value such as 1 or test.
- We can use burp-parameter-names.txt from SecLists to discover parameters.
ffuf -u http://example.com/index.php?FUZZ=test -w <wordlist> [-fs <filter_size>]
After we discovered a parameter name, we may test for their values by move the FUZZ keyword to the parameter value.
- The choice of wordlist depends on the inferred functionality of the parameter within the page. For instance, we could use a list of numbers if the parameter discovered is called
id. - We can also use wordlists that test for specific vulnerabilities (e.g. LFI-Jhaddix.txt).
ffuf -u http://example.com/index.php?<param_name>=FUZZ -w <wordlist> [-fs <filter_size>]
After finding values that causes the server to behave differently, we should test manually (e.g. with curl or Burp) to see how exactly does the server’s response deviate from the baseline. From there, we can conclude whether we have discovered a possible vulnerability.
POST Parameters
The procedure for discovering POST parameters are similar. POST parameters are appened to the end of the POST request and each parameter are separated by an &.
POST /index.php HTTP/1.1
Host: example.com
var1=value1&var2=value2
We can use -X POST to tell ffuf to fuzz using the POST method and -d to specify the data we want to send. The FUZZ keyword can also be placed within the POST data.
POST parameter name fuzz:
ffuf -w <wordlist>:FUZZ -u http://example.com/index.php -X POST -d 'FUZZ=test' \
-H 'Content-Type: application/x-www-form-urlencoded' [-fs <filter_size>]
POST parameter value fuzz:
ffuf -w <wordlist>:FUZZ -u http://example.com/index.php -X POST -d '<param_name>=FUZZ' \
-H 'Content-Type: application/x-www-form-urlencoded' [-fs <filter_size>]
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.